
Machine Learning process — Feature Engineering
Published:
An announce at begin, I’m a Data Science beginner, only share personal understandings here. I never said my opinions are all right and with huge pleasure to hear your opinions.
Why I write this article?
Nowadays, there are many Machine Learning and Deep Learning books tell us what is an algorithm and how they work, these books have many excellent examples but unfortunately, the dataset they used are all prepared, in university also. But in our work, engineers meet with noised, un-calculable, un-balanced dataset, and I was really confused and perplexed because no course told me how to do them. So I hope this blog could help some beginners when you doing your first real life project.
1, What is Feature Engineering and why it is important
As an unofficial topic, FE(Feature Engineering) has many definitions. In fact, it’s really hard to give it one exact definition, so I will show you its position in the process of a machine learning projects.
A classic machine learning process:
Subject definition / Data collection
Project model building
Data preprocessing
Feature engineering
Algorithm choose and model training
Project submission / Feedback
As you can see, FS is the bridge between data and machine learning algorithm, it can “create new features according to current features to improve our model’s result”, to some extent, FS decided the TOP of your machine learning projects, algorithms try to touch the TOP.
And, there are some guys said the one of the famous data science composition platform Kaggle “It’s a feature engineering game indeed.”
2, Mind Map of Feature Engineering
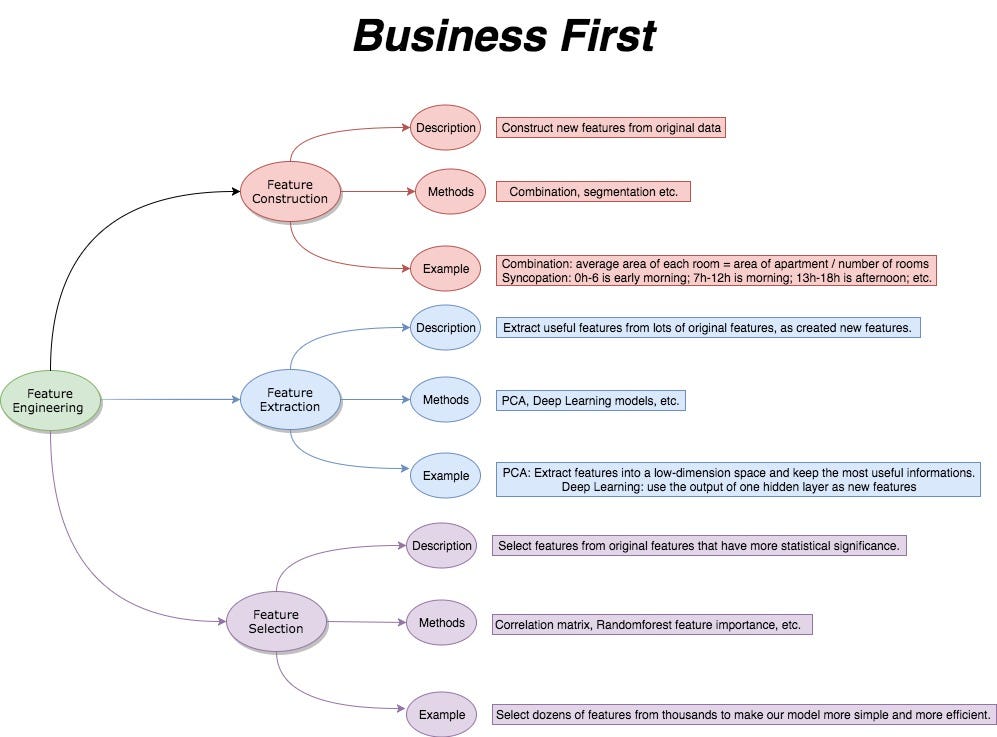
3, Explanation of each step
Business First:
For me, as an engineer Data Scientist, one point that I could never forget is that my projects serve business, their final job is making business more valuable. So the first step is going to talk with your clients, consultants or managers, clearly understand what kind of environment this project will be applied. “Connected with business” is an eternal theme.
Feature Construction:
Feature Construction is building new features from original features. This process needs us to use lots of time to research characteristics, thinking about potential problems and data structures. During this process, a brain storm is a not bad choice. Finding as many features as possible, do not care if it is useful. Design your features after several brain meeting.
The common ways are: Combination and Segmentation.
Combination: if you want to predict the apartment price, normally you have the area of the apartment and the number of rooms, so you could have its average room area as S(apartment) / N(number of rooms). Because sometimes the average area could tell more detailed information of apartment. Besides, there are many similar ways, explore them combined with business.
Segmentation: clustering algorithms only use numeric variables as distance calculation needs. In the same scenes, for the age of apartment, we could set class 1 = (0, 5), class 2=(5, 15), class 3…Why we do this? Because in client’s mind, 2 years old and 3 years old means similar.
Feature Extraction:
When you could not find any one more useful information in Feature Construction, Feature Extraction is your next step. It uses simple geometric and algebraic operations to generate more potential features, like PCA(Principal Component Analysis), ICA(Independent Component Analysis), LDA(Linear Discriminant Analysis).
Besides, Deep Learning algorithms are also usable in this process. For example, you could use the second last hidden layer’s output as your personal image model’s input variable.
Feature Selection:
After above feature works, you might have many variables then Feature Selection is your next step.
Look your Dataframe, in its dozen columns, some of them have rich information but some has poor, even someone is irrelevant data. We could use correlation relationship(feature importance) between X and Y, to detect useful features. Or use algorithms that have high generalization to calculate the feature importance, choose features according to these importances.
And in this part, we could set noised, un-balanced, multicollinearity data into normal.
4, Conclusion
Feature engineering is a cycle process, nobody could promise to get the best feature in one treat. So, what we need to do is focusing on data and combined with business, try every process for several times to arrive the best we could.